
[ad_1]
The Consortium for Python Information APIs Requirements developed the Array API customary, which goals to outline constant conduct between the ecosystem of array libraries, corresponding to PyTorch, NumPy, and CuPy. The Array API customary permits libraries, corresponding to scikit-learn, to write down code as soon as with the usual and have it work on a number of array libraries. With PyTorch tensors or CuPy arrays, it’s now potential to run computations on accelerators, corresponding to GPUs.
With the discharge of scikit-learn 1.3, we enabled experimental Array API help for a restricted set of machine studying fashions. Array API help is steadily increasing to incorporate extra machine studying fashions and performance on the event department. Scikit-learn will depend on the array_api_compat library for Array API help. array_api_compat extends the Array API customary to the primary namespaces of NumPy’s arrays, CuPy’s arrays, and PyTorch’s tensors. On this weblog put up, we cowl scikit-learn’s public interface for enabling Array API, the efficiency achieve of working on an accelerator, and the challenges we confronted when integrating Array API.
Benchmarks
Scikit-learn was initially developed to run on CPUs with NumPy arrays. With Array API help, a restricted set of scikit-learn fashions and instruments can now run with different array libraries and units like GPUs. The next benchmark outcomes are from working scikit-learn’s LinearDiscriminantAnalysis utilizing NumPy and PyTorch on a AMD 5950x CPU and PyTorch on a Nvidia RTX 3090 GPU.
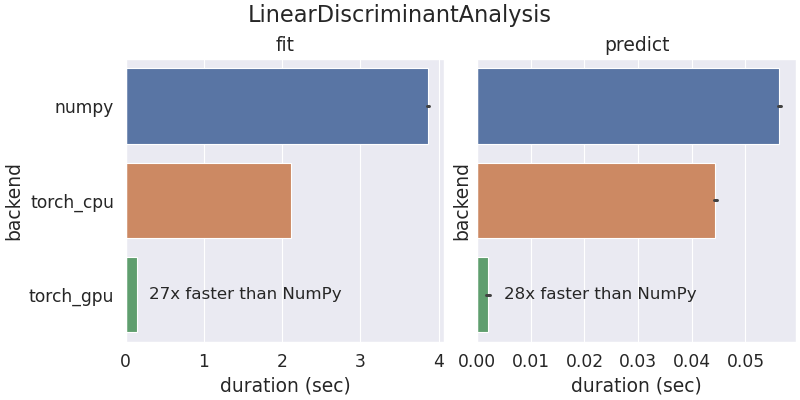
The coaching and prediction occasions are improved when utilizing PyTorch in comparison with NumPy. Operating the computation on PyTorch CPU tensors is quicker than NumPy as a result of PyTorch CPU operations are multi-threaded by default.
scikit-learn’s Array API interface
Scikit-learn prolonged its experimental Array API help in model 1.3 to help NumPy’s ndarrays, CuPy’s ndarrays, and PyTorch’s Tensors. By themselves, these array objects don’t implement the Array API specification absolutely but. To beat this limitation, Quansight engineer Aaron Meurer led the event of array_api_compat to bridge any gaps and supply Array API compatibility for NumPy, CuPy, and PyTorch. Scikit-learn straight makes use of array_api_compat for its Array API help. There are two methods of enabling Array API in scikit-learn: by way of a worldwide configuration and a context supervisor. The next instance makes use of a context supervisor:
Be aware how the estimator’s output returns an array from the enter’s array library. This following instance makes use of the worldwide configuration and PyTorch Tensors on GPUs:
A standard machine studying use case is to coach a mannequin on a GPU after which switch it to a CPU for deployment. Scikit-learn gives a non-public utility operate to deal with this gadget motion:
You possibly can study extra about Scikit-learn’s Array API help of their documentation.
Challenges
Adopting the Array API customary in scikit-learn was not a simple process and required us to beat some challenges. On this part, we cowl the 2 most important challenges:
- The Array API Normal is a subset of NumPy’s API.
- Compiled code that solely runs on CPUs as a result of it was written in C, C++, or Cython.
Array API Normal is a subset of NumPy’s API
NumPy’s API is intensive and features a huge quantity of operations. By design, the Array API customary is a subset of the NumPy API. For performance to be included within the Array API customary, it should be applied by most array libraries and broadly used. Scikit-learn’s codebase was initially written to make use of NumPy’s API. To be able to undertake the Array API, we needed to rewrite some NumPy features by way of Array API features. For instance, nanmin just isn’t part of the Array API customary, so we have been required to implement it:
The NumPy arrays are nonetheless dispatched to np.nanmin, whereas all different libraries undergo an implementation that makes use of the Array API customary.
There may be an open challenge within the Array API repo to debate bringing nanmin into the usual. Traditionally, this means of introducing new performance has been profitable. For instance, take was launched into the Array API customary in v2022.12, as a result of we proposed it within the Array API repo. The group decided that choosing parts of an array with indices was a normal operation, in order that they launched take into the up to date customary.
The Array API customary contains optionally available extensions for linear algebra and Fourier transforms. These optionally available extensions are generally applied throughout array libraries, however should not required by the Array API customary. As a machine studying library, scikit-learn extensively use the linalg module for computation. The Array API customary for NumPy arrays will name numpy.linalg and never scipy.linalg, which has refined variations. We determined to be conservative and keep backward compatibility by dispatching NumPy arrays to SciPy:
This implementation was a compromise to make sure that NumPy arrays undergo the identical code path as earlier than and have the identical efficiency traits as earlier scikit-learn variations.
Compiled Code
Scikit-learn accommodates a mix of Python code and compiled code in Cython, C, and C++. For instance, typical machine studying algorithms corresponding to random forests, linear fashions, and gradient boosted timber all have compiled code. Provided that the Array API customary is a Python API, it’s best to adapt scikit-learn’s Python code to make use of the usual. This limitation restricts the quantity of performance that may make the most of Array API.
At the moment, scikit-learn contributors are experimenting with a plugin system to dispatch compiled code to exterior libraries. Though there may be compiled code, Array API will nonetheless play a important position to get the plugin system up and working. For instance, scikit-learn generally preforms computation in Python earlier than and after dispatching to an exterior library:
With plugins, the dispatched code will ingest and return arrays that observe the Array API customary. The usual defines a typical Python interface for preprocessing and postprocessing arrays.
Conclusion
In recent times, there was rising utilization of accelerators for computation in lots of domains. The array API customary offers Python libraries like scikit-learn entry to those accelerators with the identical supply code. Relying in your code, there are numerous challenges for adopting Array API, however there are efficiency and compatibility advantages from utilizing the API. For those who observe any limitations, you might be welcome to open points on their challenge tracker. For extra details about Array API, you could watch Aaron’s SciPy presentation, learn the SciPy proceedings paper, or learn the Array API documentation.
This work was made potential by Meta funding the hassle, enabling us to make progress on this matter shortly. This matter was a longer-term aim on scikit-learn’s roadmap for fairly a while. Related steps are beneath strategy to incorporate the Array API Normal into SciPy. Because the adoption of the Array API Normal will increase, we intention to make it simpler for area libraries and their customers to raised make the most of their {hardware} for computation.
I wish to thank Aaron Meurer, Matthew Barber, and Ralf Gommers for the event of array_api_compat, which was a significant a part of this mission’s success. I additionally wish to thank Olivier Grisel and Tim Head for serving to with this mission and persevering with to push ahead on increasing help.
[ad_2]