
[ad_1]
Sorting strings in Python is one thing you could virtually take without any consideration in the event you do it on a regular basis. But, it could actually develop into surprisingly difficult contemplating all the sting instances lurking within the huge Unicode customary. Understanding Unicode isn’t a straightforward feat, so put together your self for a whirlwind tour of unusual edge instances and efficient methods of coping with them.
Be aware: On this tutorial, you’ll usually use the time period Unicode string to imply any string with non-Latin letters and characters like emoji. Nevertheless, strings consisting of Primary Latin letters additionally fall into this class as a result of the underlying ASCII desk is a subset of Unicode.
Python pioneered and popularized a strong sorting algorithm known as Timsort, which now ships with a number of main programming languages, together with Java, Rust, and Swift. Whenever you name sorted() or record.type(), Python makes use of this algorithm underneath the floor to rearrange components. So long as your sequence incorporates comparable components of suitable sorts, then you possibly can type numbers, strings, and different knowledge sorts within the anticipated order:
Except you specify in any other case, Python types these components by worth in ascending order, evaluating them pairwise. Every pair should comprise components which can be comparable utilizing both the lower than (<) or higher than (>) operator. Typically, these comparability operators are undefined for particular knowledge sorts like advanced numbers or between two distinct sorts. In these instances, a comparability will fail:
Most often, you’ll be working with homogeneous sequences comprising components of the identical kind, so that you’ll hardly ever run into this drawback within the wild. Nevertheless, issues might begin to collapse when you throw strings with non-Latin characters into the combination, resembling letters with diacritics or accents:
On this instance, you run into a typical problem related to sorting strings. When a string incorporates characters whose ordinal values lengthen past the standard ASCII vary, you then would possibly get sudden outcomes like what you could have right here. The title Łukasz finally ends up after Zbigniew, regardless that the letter Ł (pronounced like a w sound in English) happens sooner than Z within the Polish alphabet. Why’s that?
Python types strings lexicographically by evaluating Unicode code factors of the person characters from left to proper. It simply so occurs that the letter Ł has the next ordinal worth in Unicode than the letter Z, making it higher than any of the Latin letters:
Code factors are distinctive but arbitrary identifiers of Unicode characters, and so they don’t inherently agree with the alphabetical order of spoken languages. So, lexicographic sorting received’t be applicable for languages apart from English.
Completely different cultures comply with totally different guidelines for sorting strings, even after they share the identical alphabet or components of it with different cultures. For instance, the ch digraph is taken into account two separate letters (c and h) in Polish, nevertheless it turns into a stand-alone letter positioned between h and i within the Czech alphabet. This is called a contraction in Unicode.
Be aware: Language guidelines often change. As an illustration, the Spanish alphabet handled the ch and ll digraphs as single letters till 1994, when the official language regulation establishment, RAE, declared them separate.
In some unspecified time in the future, the accent ordering in French modified from backward to ahead in all places on this planet apart from Canada, which nonetheless sticks to the outdated custom:
| Accent Ordering | |
|---|---|
| France | cote, coté, côte, côté |
| Canada | cote, côte, coté, côté |
In trendy French, phrases are in contrast from left to proper. The earliest letter with an accent, which is ô within the instance above, corresponds to a higher type key, pushing the phrase to the tip of the record. Then again, in Canada, phrases are in contrast backward from proper to left, so the final accent’s place determines the ultimate order.
Relying on their geographic location worldwide, people talking the identical language might count on a barely totally different sorting order.
Furthermore, the sorting order can typically differ inside the identical tradition, relying on the context. For instance, most German cellphone books are likely to deal with letters with an umlaut (ä, ö, ü) equally to the ae, oe, and ue letter combos. Nevertheless, different nations overwhelmingly deal with these letters the identical as their Latin counterparts (a, o, u).
There’s no universally appropriate approach to type Unicode strings. It’s essential to inform Python which guidelines to use to get the specified ordering. So, how do you type Unicode strings alphabetically in Python?
Methods to Kind Strings Utilizing the Unicode Collation Algorithm (UCA)
The issue of sorting Unicode strings isn’t distinctive to Python. It’s a typical problem in any programming language or database. To deal with it, Technical Report #10 within the Unicode Technical Commonplace (UTS) describes the collation of Unicode strings, which is a constant method of evaluating two strings to determine their sorting order.
The Unicode Collation Algorithm (UCA) assigns a hierarchy of numeric weights to every character, permitting the creation of binary type keys that account for accents and different particular instances. These keys are outlined at 4 ranges that decide numerous options of a personality:
- Main: The bottom letter
- Secondary: The accents
- Tertiary: The letter case
- Quaternary: Different options
Later on this tutorial, you’ll learn to leverage these weight ranges to customise the Unicode collation algorithm by, for instance, ignoring the letter case in case-insensitive sorting.
Be aware: This hierarchical nature of character weights lets you examine type keys incrementally to extend efficiency. It additionally helps preserve reminiscence. For instance, some implementations of the UCA reap the benefits of the trie knowledge construction to effectively retailer and retrieve the weights for a given string.
Whereas the UCA provides the Default Unicode Collation Aspect Desk (DUCET), you must typically customise this default collation desk to the precise wants of a selected language and software. It’s just about unimaginable to make sure the specified type order for all languages utilizing just one character desk. Due to this fact, software program libraries implementing the UCA often depend on the Widespread Locale Information Repository (CLDR) to offer such customization.
This repository incorporates a number of XML paperwork with language-specific data. For instance, the collation guidelines for sorting textual content in Polish clarify the connection between the letters z, ź, and ż in each uppercase and lowercase:
With out going into the technical particulars of the collation rule syntax, you possibly can observe that z comes earlier than ź, which comes earlier than ż. The identical rule applies no matter whether or not the letters are uppercase or lowercase.
To make use of the Unicode Collation Algorithm in Python, you possibly can set up the pyuca library into your digital setting. Whereas this library is barely out of date and solely helps Unicode as much as model 10, you possibly can obtain the newest DUCET desk from Unicode’s official web site and provide the corresponding filename when making a collator object:
Alternatively, you possibly can create a collator occasion with out specifying the file, during which case it’ll use an older model that was distributed with the library. Calling the collator’s .sort_key() technique on a string reveals a tuple of weights that you need to use in a comparability.
Discover that weights on the first index in each tuples are equivalent, which means that the letters z and ż are basically handled as equal, disregarding accents. That is an meant habits of the default collation desk in UCA if you go away it with out customization, however as you’ll quickly study, this isn’t very best.
The second weight, which corresponds to the next letter, determines the sorting order of each strings. The remaining weights are irrelevant at this level.
You’ll be able to type a sequence of Unicode strings utilizing pyuca by offering the reference to your collator’s .sort_key() technique because the key operate:
Keep in mind to omit the parentheses on the finish of the strategy title to keep away from calling it! You wish to go a reference to a operate or technique that Python will later name for every merchandise within the record. If you happen to have been to name your technique right here, then it might execute instantly, returning a single worth as a substitute of the callable object that sorted() expects.
As you possibly can see, the default collation desk in UCA doesn’t conform to the Polish language guidelines, because the title Żaneta ought to type after Zbigniew. Sadly, pyuca doesn’t allow you to specify customized guidelines to alleviate that. Whilst you might manually attempt modifying the downloaded textual content file earlier than supplying it to the collator, it’s a tedious and error-prone activity.
Not solely is pyuca restricted on this regard, nevertheless it additionally hasn’t been actively maintained for a number of years now. As a pure-Python library, it’d negatively have an effect on the efficiency of extra demanding purposes. General, you’re higher off discovering an alternate software like PyICU, which is a Python binding to IBM’s open-source Worldwide Elements for Unicode (ICU) library applied in C++ and Java.
Be aware: PyICU is simply out there as a supply distribution, so you must have a C++ compiler and, on choose platforms, a number of third-party dependencies to put in it. Observe the official directions within the README file in the event you face any difficulties.
After you have PyICU put in, getting began is fairly easy and doesn’t look a lot totally different than utilizing pyuca. Right here’s an instance of how one can create a collator and provide an non-obligatory algorithm particular to a given language:
On this case, you utilize the Polish taste of the Unicode collation guidelines, which leads to the anticipated type order of names. To get an entire record of all out there languages, use the next code snippet:
These languages are constructed into the library and shipped with it utilizing a binary format, independently of your working system, which can assist a unique set of languages. You should use any of those to customise your collator occasion.
Moreover, it’s possible you’ll construct a collator from scratch with totally customized guidelines expressed in a format much like the one you’ve seen within the XML file earlier than:
You’ve created an occasion of the RuleBasedCollator with the collation guidelines for sorting textual content in Polish, which you borrowed from the Widespread Locale Information Repository (CLDR). Because of this, the Polish names are actually organized appropriately.
That is barely scratching the floor of what’s potential with PyICU. The library isn’t only for sorting Unicode strings. It could additionally aid you develop multilingual purposes for customers worldwide.
The most important draw back of PyICU is its doubtlessly cumbersome set up. It’s additionally a comparatively massive library, each by way of measurement on disk and an intensive API. If one in every of these turns into a deal-breaker for you, or in the event you can’t use any third-party libraries, then contemplate various choices.
Subsequent up, you’ll study concerning the locale module in Python’s customary library.
Leverage Python’s locale Module to Kind Unicode Strings
Python’s official sorting how-to information recommends utilizing the usual library module locale to respect cultural and geographical conventions when sorting strings. It’s a Python interface to C localization features that expose the regional settings on a POSIX-compatible working system. A few of them embrace:
- Handle and cellphone codecs
- Foreign money image
- Date and time format
- Decimal image (for instance, level vs comma)
- Language
- Measurement items
- Paper measurement (for instance, A4 vs Letter)
These parameters are collectively referred to as locale. You’ll be able to management them globally by a set of setting variables, like LC_ALL, which is able to apply to your whole working system. Alternatively, you possibly can selectively override a few of them inside your program when it runs.
The locale is about a lot greater than a language. For instance, English has a number of dialects spoken on many continents. Every dialect might have distinct traits, resembling these:
| American | British | |
|---|---|---|
| Spelling | shade | color |
| Vocabulary | truck | lorry |
| Measurement System | imperial | metric |
| Foreign money | {dollars} | kilos |
| Pronunciation | uh-loo-muh-nuhm | al-yoo-min-ee-um |
Even areas of the identical nation typically exhibit slight variations. To account for these potential variations, a locale identifier consists of two necessary and two non-obligatory components:
- Language: A two-letter, lowercase language code (ISO 639)
- Territory: A two-letter, uppercase nation code (ISO 3166)
- Charmap: An non-obligatory character encoding
- Modifier: An non-obligatory modifier for particular locale variations
For instance, the identifier ca_ES.UTF-8@valencia represents the Catalan language spoken in Spain utilizing the Valencian dialect with the UTF-8 character encoding. Then again, en_US is one other legitimate identifier that corresponds to English spoken in the US together with your working system’s default character encoding.
If you happen to’re on macOS or a Linux distribution, then you possibly can verify your present locale by typing the locale command at your command immediate:
You get details about particular locale classes and their values. The LC_COLLATE class controls how strings are in contrast, which determines the sorting order of Unicode strings.
To disclose the whole record of accessible locales put in in your system, append the -a flag to the locale command:
The C and POSIX locales are defaults defining a minimal set of regional settings that should adjust to the C programming language on a POSIX-compliant system.
To put in a further locale, choose one from an inventory of the supported locales after which generate the corresponding localization information from the chosen template. If you happen to’re on Linux, then you possibly can record the supported locales by revealing the contents of a particular file:
These instructions allow a brand new locale for Portuguese as spoken in Brazil. If you happen to’d like your working system to choose it up, then you should additionally set up the corresponding language pack earlier than altering the present locale:
The package deal title that you must set up might fluctuate. As an illustration, the one above is appropriate for Linux distributions primarily based on Debian. After altering the present locale, a lot of the customary Unix instructions will replicate that of their output:
Whenever you attempt to print the contents of a lacking file with cat, you get an error message in Portuguese. Be aware that setting setting variables has solely a short lived impact that can final till you shut the present terminal session. To use the brand new locale completely, edit your shell configuration file accordingly.
Now, how do you management the locale in Python? You’ve already seen that the default lexicographic sorting in Python might result in incorrect outcomes. To repair that, you possibly can attempt utilizing locale.strxfrm(), which transforms a string right into a locale-aware counterpart, because the type key:
Relying in your present locale, the record might find yourself sorted otherwise than with out the customized key. Nevertheless, the outcome can nonetheless be incorrect if you don’t specify the proper locale. In such a case, Python depends in your working system’s default locale, which can be unsuitable for the given language.
Be aware: You’ll additionally discover one other operate locale.strcoll(), which compares two strings in keeping with the present locale. It was handy in legacy Python variations, whose sorting features accepted the cmp parameter, which was dropped in Python 3.
When sorting strings, you all the time wish to override the collation guidelines to match the language in query:
Finally, you get the anticipated outcome by setting the collation class to the Polish locale.
Be aware: You could have the right locale put in in your working system earlier than utilizing it in your applications. In any other case, Python will silently fall again to the working system’s default locale with out elevating an error:
If the default locale is unset or doesn’t match the language that you simply want to work with, you then’ll nonetheless get an incorrect sorting order.
Sadly, calling locale.setlocale() is a worldwide setting that received’t aid you with sorting phrases in multiple language concurrently. It additionally isn’t thread-safe, so that you’d sometimes invoke it as soon as after beginning your program, versus dealing with the incoming HTTP requests in a multi-threaded net software, for instance.
Aside from having the ability to deal with at most one language at a time, locale will solely work on POSIX-compliant programs, making it much less transportable than different options. It requires the right locale to be put in in your system, and it helps ISO 14651, which is a subset of the whole Unicode Collation Algorithm. That stated, it might be sufficient in additional easy use instances.
Transliterate Overseas Characters Into Latin Equivalents
You don’t all the time care about exact collation guidelines of international languages. As a substitute, it’s possible you’ll desire to make the type order seem appropriate to an English speaker by changing every string right into a Latin script that finest approximates the unique. In linguistics, such conversion is called the romanization of textual content, and it could actually take a number of kinds, together with a mix of those:
- Transliteration: Swapping letters from one script with one other
- Transcription: Representing a international script phonetically
The fundamental concept behind transliteration is to switch each non-ASCII letter with its closest Latin counterpart earlier than evaluating the strings. It’s also possible to use this system to characterize Unicode on a legacy system that solely helps ASCII characters or to create a clear URL. Be aware that merely stripping any character past ASCII would alter the textual content, eradicating an excessive amount of data.
Listed here are a number of examples of phrases transliterated from totally different alphabets:
| Alphabet | Unique | Transliteration |
|---|---|---|
| Cyrillic | Петроград | Petrograd |
| Greek | Κνωσός | Knosos |
| Kurdish | Xirabreşkê | Xirabreske |
| Norwegian | Svolvær | Svolvaer |
| Polish | Łódź | Lodz |
This technique works finest with alphabets derived from Latin or Greek, versus different alphabets like Arabic, Chinese language, or Hebrew. To deal with non-Roman languages, you’ll want to plot a method of transcribing sounds related to the visible symbols.
For instance, check out these metropolis names and their transcriptions:
| Alphabet | Unique | Transcription |
|---|---|---|
| Arabic | الرياض | Riyadh |
| Chinese language | 北京 | Beijing |
| Hebrew | יְרוּשָׁלַיִם | Jerusalem |
| Japanese | 東京 | Dongjing (Tokyo) |
| Korean | 서울 | Seoul |
Transcribing a given textual content is inherently extra difficult than transliterating it, so that you’ll solely contemplate transliteration any more.
One approach to strip accents or diacritics from Latin letters is by benefiting from Unicode equivalence, which states that various sequences of code factors can encode semantically equivalent characters. Even when two Unicode strings look the identical to a human reader, they might have totally different lengths and contents, affecting the type order. For instance, the letter é has two canonically equal Unicode representations:
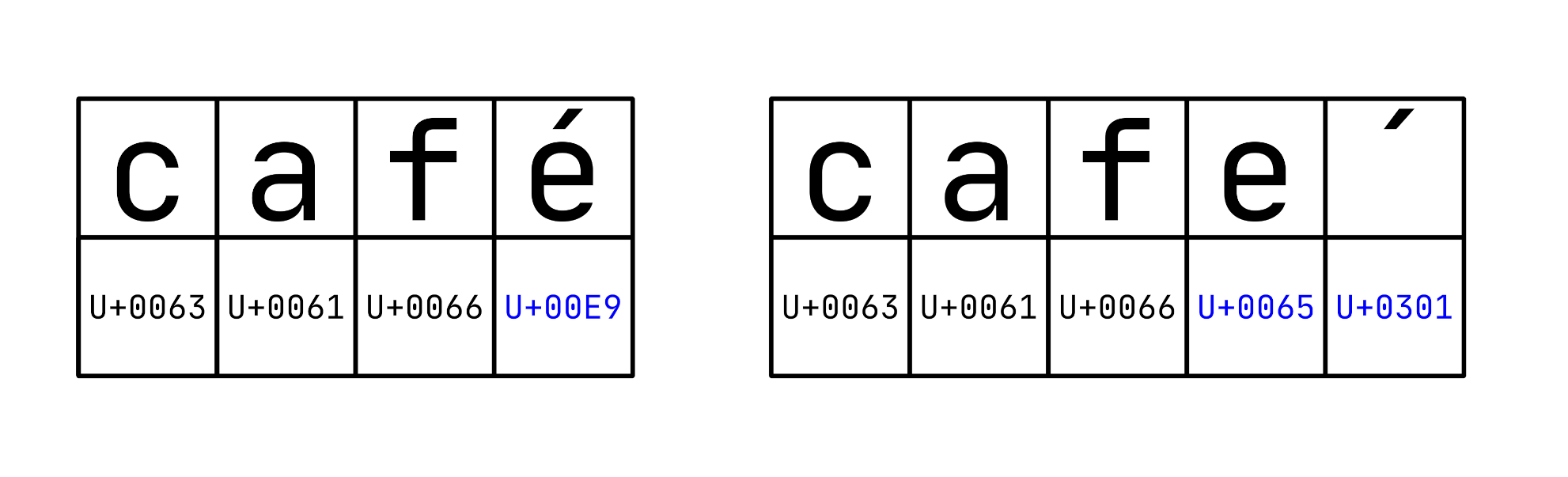
The illustration on the left encodes the final letter within the phrase café utilizing Unicode code level U+00E9. Conversely, the illustration on the proper encodes the identical letter utilizing two code factors: U+0065 for the Latin letter e, adopted by U+0301, which is the acute accent that mixes with the previous letter. The combining characters like these don’t stand on their very own however modify how different characters render.
Be aware: These various Unicode string representations as code factors are impartial of their encoded byte representations, resembling UTF-8 or UTF-16.
The Unicode customary specifies 4 regular kinds and the corresponding algorithms for changing between them by a course of known as Unicode normalization. In Python, you need to use the standard-library module unicodedata to carry out such a normalization:
Discover that the 2 variables render the identical glyphs if you consider them, however the underlying strings have totally different lengths and don’t examine as equal. Normalizing both of the strings into the frequent Unicode illustration permits for an apples-to-apples comparability.
Be aware: Some fonts might miss sure glyphs or render them in an odd method. For instance, in case your font doesn’t comprise both the precomposed or decomposed variant of the acute accent, you then received’t see the entire image:
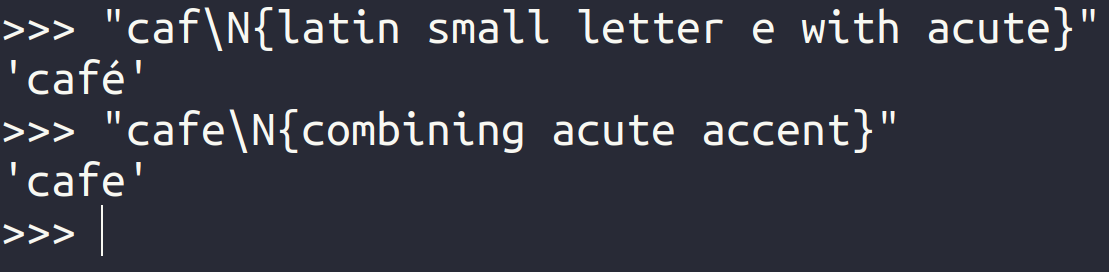
On this case, regardless that the second string incorporates two separate code factors representing the letter é, it seems as a plain e on the display. To study extra about fonts, try Selecting the Finest Coding Font for Programming.
Unicode’s NFD type lets you decompose a Unicode string into plain Latin letters whereas discarding any combining characters that will outcome from this normalization. To make your life simpler, outline the next helper operate, which you’ll evolve later:
After decomposing a string, you .encode() it right into a sequence of bytes whereas ignoring ordinal values that may’t match within the ASCII vary. Then, you .decode() the ensuing bytes right into a Python string once more, which you come to the caller.
To confirm in case your operate works as anticipated, you possibly can take a look at it towards a number of pangrams, that are humorous and sometimes nonsensical sentences containing each letter from the given alphabet:
You outline and iterate by a Python dictionary of three pangrams earlier than printing their transliterations on the display. Sadly, whereas your answer works advantageous with most letters, it typically removes them as a substitute of discovering a substitute.
Apparently, sure letters with diacritics don’t have a corresponding combining character in Unicode. For instance, the Polish letter Ł is a standalone character with an inseparable stroke, making it already normalized:
Making an attempt to decompose Ł yields the identical letter as a result of it’s already decomposed. You’ll be able to mitigate this undesirable habits by permitting your transliteration operate to simply accept an non-obligatory character mapping to .translate() the string with:
You utilize a generator expression to organize a string with all of the combining characters in Unicode. If the caller supplied a customized mapping, you then separate its keys and values into two strings known as src and dst, which you go to str.maketrans() to construct a translation desk. In any other case, you construct a translation desk that simply removes all combining characters. Lastly, you normalize the textual content to the NFD type earlier than making use of the interpretation desk.
This new operate helps cope with particular instances, nevertheless it doesn’t scale too effectively, as you continue to need to manually construct the interpretation desk your self every time. Furthermore, it doesn’t allow you to map a single code level, resembling U+00E6 representing the letter æ, into multiple character, which could be vital:
To deal with most nook instances of transliteration and even handle components of transcription, you possibly can set up Unidecode or one other third-party library:
In contrast to your earlier makes an attempt at transliteration, calling the unidecode() operate could make the ensuing string longer than the unique, so no data will get misplaced in the course of the course of.
Be aware: It’s also possible to do transliteration with the PyICU library that you simply’ve seen earlier than:
When making a transliterator occasion, you should present the supply and goal writing script identifiers.
Now, if you wish to type a sequence of Unicode strings in keeping with their transliterations however with out altering them, then you need to use your transliteration operate as the type key:
This received’t offer you an correct outcome, nevertheless it ought to look proper to most English-speaking audiences.
One other frequent problem related to sorting Unicode strings, which additionally requires Unicode normalization, is case-insensitive comparability. It’s fairly widespread in real-life situations, so that you’ll examine it now.
Carry out Case-Insensitive Sorting of Unicode Strings
Whenever you type strings comprising solely ASCII characters, then uppercase letters all the time come first due to their underlying ordinal values:
Whether or not that is desired is determined by the language and context. Both method, string sorting in Python is case-sensitive by default. To ignore the letter case when evaluating strings, you possibly can convert all letters to lowercase or uppercase and use them as the type key:
Now, your strings are sorted alphabetically no matter their letter case. Sadly, whereas this fast repair works for many English phrases, it breaks down when encountering accented letters just like the French é:
Below the floor, you continue to type your strings lexicographically utilizing character code factors. So, regardless that you examine a lowercase letter é towards lowercase h, the latter comes first as a result of it has a smaller ordinal worth.
It’s price noting that the idea of uppercase and lowercase letters isn’t common to all writing programs prefer it seems within the Latin alphabet. In addition to, as you spend extra time working with international texts, it’s possible you’ll run into some actually shocking edge instances in Unicode.
As an illustration, the German letter ß (sharp S) by no means happens firstly of a phrase. Due to this fact, for a very long time, it was solely out there as a lowercase letter with out an uppercase variant within the alphabet:
Whenever you attempt uppercasing it in Python, you get a double-S digraph as a substitute. However, some fonts do present a capital type of sharp S, and Unicode even assigns a devoted code level (U+1E9E) to it:
However, you possibly can’t restore its authentic capital type utilizing chained calls to .decrease() and .higher() in Python. On the identical time, numerous dialects of the German language in nations like Switzerland don’t use sharp S in any respect.
One other fascinating quirk is the Greek letter Σ (sigma), which has two various lowercase kinds relying on the place you set it in a phrase:
On the finish of a phrase, a lowercase sigma takes the last type ς, however in all places else, it seems because the extra conventional σ.
Uppercase variations of the Latin b, Greek β, and Cyrillic в have an equivalent visible look regardless of having distinct code factors:
As you possibly can see, there are far too many nook instances to try to cowl all of them by hand.
Luckily, Python 3.3 launched a brand new string technique known as str.casefold(), which provides assist for Unicode case folding for the aim of caseless comparability of textual content. Based on the Unicode glossary, folding permits you to briefly ignore sure distinctions between characters. Typically, case folding works equally to lowercasing a string, however there are a number of notable exceptions:
Particular instances just like the German sharp S are dealt with otherwise, letting you examine phrases like GROSS and groß as equal. Additionally, ranging from Unicode model 8.0, Cherokee letters like U+13AD representing Ꭽ fold to uppercase letters in an effort to give the stability ensures required by case folding.
That’s nice! Are you able to now use str.casefold() as a substitute of str.decrease() or str.higher() as your key operate for case-insensitive sorting of Unicode strings in Python? Effectively, not precisely.
Initially, it received’t handle the issue related to arbitrary ordinal values of accented letters. Secondly, the strings that you simply want to examine should share a typical Unicode illustration. As a result of case folding doesn’t all the time protect the traditional type of the unique string, you must typically carry out the normalization after folding your strings.
So, to implement a case-insensitive key operate for sorting strings, as specified by the Unicode Commonplace, you should mix str.casefold() with Unicode normalization:
Utilizing the functools module, you outline a partial operate nfd() that takes a string as an argument and applies the Unicode canonical decomposition to it. You then name this operate twice to normalize the string earlier than and after the case folding. Calling it twice acts as an additional safeguard towards uncommon edge instances involving one specific combining character in Greek that requires particular therapy to completely adjust to the Unicode Commonplace.
Be aware: This code is tailored from Python’s official Unicode how-to information, which explains the best way to appropriately examine strings in a case-insensitive method. It follows the formal specification from Part 3.13 Default Case Algorithms in Chapter 3 of the Unicode Commonplace.
Having this new key operate in place, now you can type your French animals alphabetically whereas ignoring the letter case:
Success! Whereas exploring the quirks of Unicode is undoubtedly an incredible studying expertise, you possibly can obtain the same impact with a lot much less effort utilizing the Unicode Collation Algorithm (UCA).
If you have already got the PyICU library put in, then you possibly can ignore the letter case totally by tweaking your collator object:
By lowering the collator’s power to secondary, you make it disregard the subsequent ranges of character weights in UCA, together with the tertiary stage liable for uppercase and lowercase variations. It’s also possible to resolve whether or not uppercase letters ought to come first or the opposite method round by configuring the CaseFirst parameter.
Be aware: Within the pure-Python pyuca library, lowercase letters all the time come earlier than their uppercase counterparts, and also you don’t have management over this habits:
The burden values embedded within the Default Unicode Collation Aspect Desk (DUCET), which the library makes use of underneath the hood, decide such ordering. Discover that this breaks the steadiness of the sorting algorithm, as the 2 elephants swapped positions within the record.
Evaluating strings in a case-insensitive method is without doubt one of the most typical necessities when sorting or trying to find strings. However, there are lots of extra particular instances that you could be want to contemplate, just like the dealing with of punctuation, whitespace characters, or numbers. Libraries like PyICU allow you to customise the collation guidelines accordingly.
Subsequent up, you’ll study concerning the pure type order, which your customers would possibly count on in some situations.
Kind Strings With Numbers in Pure Order
Arranging strings within the pure type order is much like alphabetical sorting, nevertheless it takes digits that could be a part of the string into consideration. A typical instance of that will contain itemizing a listing stuffed with log information whose names comprise a model quantity:
Whereas such ordering appears to be like pure to most people, the lexicographic sorting in Python and different programming languages produces a less-than-intuitive outcome for a similar enter sequence of strings:
As a result of Python compares your strings by worth, all digits find yourself handled as strange character code factors as a substitute of numbers. So, a string that incorporates "10" comes earlier than "2", disrupting the pure ordering of numbers. To repair this, you possibly can attempt utilizing common expressions by isolating the person alphanumeric chunks of the string into separate components to check:
Your type key operate, natural_order(), returns a tuple whose components are both strings or integers. This compound key permits Python to check the corresponding tuple components one after the other from left to proper utilizing the suitable comparability for the info kind.
Be aware that this can be a pretty easy implementation that may’t deal with signed numbers, floating-point numbers, or any of the sting instances that you simply’ve discovered thus far. To cope with particular instances like locale-aware and case-insensitive sorting, you must attain for a hassle-free library like natsort, which performs properly with PyICU:
Use the locale module to set the specified language and nation code. When natsort detects PyICU in your digital setting, it’ll use it and solely fall again to locale if it could actually’t discover this third-party library. Simply be sure to set the locale earlier than importing natsort. In any other case, it’ll fall again to your working system’s default locale.
Up to now, you’ve been sorting plain strings in Python, which is never the case in real-world programming tasks. You’re extra prone to type advanced knowledge buildings or objects by their particular attributes. Within the subsequent part, you’ll learn to just do that.
Kind Advanced Objects by Extra Than One Key
Ordering folks by title is a traditional instance of sorting advanced objects, which regularly comes up in follow. Suppose that you must compile an inventory of staff in an organization in keeping with their first and final names for an annual report. You’ll be able to leverage Python’s named tuple to characterize every individual:
As a result of every individual is a tuple consisting of the primary and final names, Python is aware of the best way to examine these objects with out requiring you to implement any particular strategies in your class. Whenever you go an inventory of Individual cases to the sorted() operate, every object turns into a compound key. Sadly, sorting nonetheless depends on the lexicographic order of Unicode strings, so that you don’t get the anticipated outcome.
You’ll be able to repair the state of affairs by defining your personal compound key utilizing the pyuca collator:
This time, the outcome comes out a bit higher however nonetheless not fairly appropriate, as Zbigniew is positioned after Żaneta. Do you bear in mind why?
It’s the identical drawback that you simply bumped into earlier whereas utilizing pyuca, which depends on the default collation desk with out letting you customise it for the precise locale. Luckily, you possibly can outline a compound key utilizing PyICU equally effectively:
General, this code appears to be like very a lot the identical however makes use of a barely totally different API that exposes the locale customization. Whenever you configure appropriate language guidelines, you get the specified outcome.
If you happen to’re curious, then you possibly can experiment by swapping the attributes in your compound key to watch how that impacts the sorting order:
On this case, you’ve sorted your staff primarily by final title. You then type people who share the identical final title by first title.
Now you know the way to type advanced objects utilizing a customized compound key, which takes locale-aware Unicode collation guidelines into consideration. With that talent underneath your belt, you conclude this complete tutorial.
Conclusion
Congratulations on efficiently navigating the intricate activity of sorting Unicode strings in Python! You’re now conscious of the potential hurdles that you simply would possibly face in real-world tasks, in addition to methods to beat them. You’ve gained perception into the Unicode Collation Algorithm (UCA) and several other Python libraries that expose it to you.
You understand the distinction between alphabetical and lexicographic sorting, perceive what collation guidelines are, and might clarify how the canonical decomposition in Unicode works. You’re in a position to customise your sorting order to make it locale-aware, reflecting particular cultural conventions. Moreover, you possibly can romanize non-Latin texts by transliteration and transcription for compatibility with programs that solely assist ASCII.
Your newfound experience permits you to safely carry out case-insensitive sorting and pure sorting inside the Unicode area. Lastly, you possibly can assemble compound type keys for ordering advanced objects primarily based on a subset of attributes. Armed with this thorough data, you’re effectively ready to develop dependable multilingual purposes catered to a worldwide person base.
[ad_2]