")
[ad_1]
On this article we are going to clarify how Open Supply ChatGPT options work and the way you should use them to construct your personal ChatGPT clone free of charge. By the tip of this text you should have a superb understanding of those fashions and can have the ability to examine and use them.
There are numerous advantages of utilizing open supply massive language fashions that are options to ChatGPT. A few of them are listed under.
Llama
Introduction : Llama
Llama stands for Massive Language Mannequin Meta AI. It features a vary of mannequin sizes from 7 billion to 65 billion parameters. Meta AI researchers centered on scaling the mannequin’s efficiency by growing the quantity of coaching knowledge, slightly than the variety of parameters. They claimed the 13 billion parameter mannequin outperformed 175 billion parameters of GPT-3 mannequin. It makes use of the transformer structure and was skilled on 1.4 trillion tokens extracted by internet scraping Wikipedia, GitHub, Stack Trade, Books from Mission Gutenberg, scientific papers on ArXiv.
Python Code : Llama
# Set up Bundle
pip set up llama-cpp-python
from llama_cpp import Llama
llm = Llama(model_path="./fashions/7B/ggml-model.bin")
output = llm("Q: Title the planets within the photo voltaic system? A: ", max_tokens=128, cease=["Q:", "n"], echo=True)
print(output)
Within the mannequin path, it’s essential to have weights for Llama in GGML format after which retailer them into the fashions folder. You possibly can search it on Hugging Face web site. See one in every of them right here
Llama 2
What’s New in Llama 2
Listed below are among the key variations between Llama 2 and Llama:
Coaching knowledge: Llama 2 is skilled on 40% extra tokens than Llama, a complete of two trillion tokens. This provides it a bigger data base and permits it to generate extra correct responses.Mannequin measurement: Llama 2 is on the market in three sizes: 7 billion parameters, 13 billion parameters, and 70 billion parameters. Whereas, the utmost measurement of Llama is 65 billion parameters.Chat optimization: Llama 2-Chat is a specialised model of Llama 2 that’s optimized for partaking in two-way conversations. It has been skilled on a dataset of human conversations, which permits it to generate extra pure and interesting responses.Security and bias mitigation: Llama 2 has been skilled with a concentrate on security and bias mitigation. Because of this it’s much less prone to generate poisonous or dangerous content material.Open supply: Llama 2 is open supply, which signifies that anybody can use it for analysis or business functions. Whereas, Llama cannot be used for business functions.
Python Code : Llama 2
Llam2: 7 Billion Parameters
To run Llama2 7B mannequin, refer the code under. The next code makes use of a 4-bit quantization approach that reduces the scale of the LLM, which may make it simpler to deploy and use on sytems with restricted reminiscence.
%cd /content material !apt-get -y set up -qq aria2 !git clone -b v1.3 https://github.com/camenduru/text-generation-webui %cd /content material/text-generation-webui !pip set up -r necessities.txt !pip set up -U gradio==3.28.3 !mkdir /content material/text-generation-webui/repositories %cd /content material/text-generation-webui/repositories !git clone -b v1.2 https://github.com/camenduru/GPTQ-for-LLaMa.git %cd GPTQ-for-LLaMa !python setup_cuda.py set up !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/uncooked/major/config.json -d /content material/text-generation-webui/fashions/Llama-2-7b-Chat-GPTQ -o config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/uncooked/major/generation_config.json -d /content material/text-generation-webui/fashions/Llama-2-7b-Chat-GPTQ -o generation_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/uncooked/major/special_tokens_map.json -d /content material/text-generation-webui/fashions/Llama-2-7b-Chat-GPTQ -o special_tokens_map.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/resolve/major/tokenizer.mannequin -d /content material/text-generation-webui/fashions/Llama-2-7b-Chat-GPTQ -o tokenizer.mannequin !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/uncooked/major/tokenizer_config.json -d /content material/text-generation-webui/fashions/Llama-2-7b-Chat-GPTQ -o tokenizer_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/resolve/major/gptq_model-4bit-128g.safetensors -d /content material/text-generation-webui/fashions/Llama-2-7b-Chat-GPTQ -o gptq_model-4bit-128g.safetensors %cd /content material/text-generation-webui !python server.py --share --chat --wbits 4 --groupsize 128 --model_type llama
Llam2: 13 Billion Parameters
To run Llama2 13B mannequin, refer the code under.
%cd /content material !apt-get -y set up -qq aria2 !git clone -b v1.8 https://github.com/camenduru/text-generation-webui %cd /content material/text-generation-webui !pip set up -r necessities.txt !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/resolve/major/model-00001-of-00003.safetensors -d /content material/text-generation-webui/fashions/Llama-2-13b-chat-hf -o model-00001-of-00003.safetensors !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/resolve/major/model-00002-of-00003.safetensors -d /content material/text-generation-webui/fashions/Llama-2-13b-chat-hf -o model-00002-of-00003.safetensors !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/resolve/major/model-00003-of-00003.safetensors -d /content material/text-generation-webui/fashions/Llama-2-13b-chat-hf -o model-00003-of-00003.safetensors !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/uncooked/major/mannequin.safetensors.index.json -d /content material/text-generation-webui/fashions/Llama-2-13b-chat-hf -o mannequin.safetensors.index.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/uncooked/major/special_tokens_map.json -d /content material/text-generation-webui/fashions/Llama-2-13b-chat-hf -o special_tokens_map.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/resolve/major/tokenizer.mannequin -d /content material/text-generation-webui/fashions/Llama-2-13b-chat-hf -o tokenizer.mannequin !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/uncooked/major/tokenizer_config.json -d /content material/text-generation-webui/fashions/Llama-2-13b-chat-hf -o tokenizer_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/uncooked/major/config.json -d /content material/text-generation-webui/fashions/Llama-2-13b-chat-hf -o config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-chat-hf/uncooked/major/generation_config.json -d /content material/text-generation-webui/fashions/Llama-2-13b-chat-hf -o generation_config.json %cd /content material/text-generation-webui !python server.py --share --chat --load-in-8bit --model /content material/text-generation-webui/fashions/Llama-2-13b-chat-hf
Alpaca
Introduction : Alpaca
A group of researchers from Stanford College developed an open-source language mannequin known as Alpaca. It’s based mostly on Meta’s large-scale language mannequin Llama. The group used OpenAI’s GPT API (text-davinci-003) to wonderful tune the Llama 7 billion (7B) parameters sized mannequin. The purpose of the group is to make AI obtainable for everybody free of charge in order that academicians can do additional analysis with out worrying about costly hardwares to execute these memory-intensive algorithms. Though these open supply fashions are usually not obtainable for business use, small companies can nonetheless put it to use for constructing their very own chatbots.
How does Alpaca work
The Stanford group started their analysis with the smallest language mannequin amongst Llama fashions, which was the Llama 7B mannequin, and pre-trained it with 1 trillion tokens. They began with the 175 human-written instruction-output pairs from the self-instruct seed set. They then used OpenAI API to ask ChatGPT to generate extra directions utilizing the seed set. It’s to acquire roughly 52,000 pattern conversations, which the group used to additional fine-tune the Llama fashions utilizing Hugging Face’s coaching framework.

Llama comes at a number of sizes – 7B, 13B, 30B, and 65B parameters. Alpaca was additionally prolonged to 13B, 30B, and 65B fashions.
Efficiency : Alpaca
The Alpaca mannequin was examined towards ChatGPT in duties comparable to e-mail creation, social media, and productiveness instruments, and Alpaca received 90 occasions whereas ChatGPT received 89 occasions. The mannequin can be utilized in actual world for numerous functions. Will probably be an important assist for researchers for moral AI and cyber safety actions like detecting scamming and phishing.
Limitations : Alpaca
Like business model of ChatGPT, Alpaca additionally has related limitations i.e. suffers from hallucinations, toxicity, and stereotypes. In different phrases, it may be used to generate textual content which spreads misinformation, racism and hatred in the direction of weak sections of society.
Reminiscence Necessities : Alpaca
It might’t run on CPU, requires GPU. For 7B and 13B fashions it requires a single GPU with 12GB of RAM. For 30B mannequin you want extra system assets.
Python Code : Alpaca
I’ve created Colab code. You should utilize it to your reference. Since I’m utilizing free model of Colab, I’m working smallest mannequin 7B. You possibly can change it to 13B and 30B.
Much like the business interface of ChatGPT, the output of the code leads to an internet interface created in Gradio. Furthermore, you should use this interface for demonstration functions and share it with colleagues or purchasers.
Create an setting with Python 3.9
import sys
sys.path.append("/usr/native/lib/python3.9/site-packages")
The command under nvidia-smi is a command to show details about the GPU utilization and efficiency.
!nvidia-smi
Obtain Git Repository
!git clone https://github.com/deepanshu88/Alpaca-LoRA-Serve.git
Set up required packages
%cd Alpaca-LoRA-Serve !python3.9 -m pip set up -r necessities.txt
Select measurement of the mannequin
base_model="decapoda-research/llama-7b-hf" finetuned_model="tloen/alpaca-lora-7b"
Run the applying
!python3.9 app.py --base_url $base_model --ft_ckpt_url $finetuned_model --share
Full Code
import sys
sys.path.append("/usr/native/lib/python3.9/site-packages")
!nvidia-smi
!git clone https://github.com/deepanshu88/Alpaca-LoRA-Serve.git
%cd Alpaca-LoRA-Serve
!python3.9 -m pip set up -r necessities.txt
base_model="decapoda-research/llama-7b-hf"
finetuned_model="tloen/alpaca-lora-7b"
!python3.9 app.py --base_url $base_model --ft_ckpt_url $finetuned_model --share
The above code helps bigger language fashions than 7B. See the reference under. 7B and 13B can be utilized in free model of colab. For 30B, it’s essential to go for premium model of colab.
Doable values of --base_url
- decapoda-research/llama-7b-hf - decapoda-research/llama-13b-hf - decapoda-research/llama-30b-hf
Doable values of --ft_ckpt_url
- tloen/alpaca-lora-7b - chansung/alpaca-lora-13b - chansung/alpaca-lora-30b
Output : Alpaca
See the output under whereby I requested two comparatively two simple questions. One associated to a generic matter and the opposite associated to coding. It answered each the questions accurately.

GPT4All
Introduction : GPT4All
Nomic AI Workforce took inspiration from Alpaca and used GPT-3.5-Turbo OpenAI API to gather round 800,000 prompt-response pairs to create 430,000 coaching pairs of assistant-style prompts and generations, together with code, dialogue, and narratives. 800K pairs are roughly 16 occasions bigger than Alpaca. The perfect half concerning the mannequin is that it might probably run on CPU, doesn’t require GPU. Like Alpaca additionally it is an open supply which is able to assist people to do additional analysis with out spending on business options.
How does GPT4All work
It really works just like Alpaca and based mostly on Llama 7B mannequin. The group wonderful tuned fashions of Llama 7B and last mannequin was skilled on the 437,605 post-processed assistant-style prompts.
Efficiency : GPT4All
In pure language processing, perplexity is used to judge the standard of language fashions. It measures how stunned a language mannequin can be to see a brand new sequence of phrases it has not encountered earlier than, based mostly on its coaching knowledge. A decrease perplexity worth signifies that the language mannequin is healthier at predicting the subsequent phrase in a sequence, and subsequently, is extra correct. The Nomic AI Workforce claims that their fashions has decrease perplexities than Alpaca. The actual accuracy will depend on the sort of prompts you’ve got. Alpaca could have higher accuracy in some circumstances.
Reminiscence Necessities : GPT4All
It might run on a CPU with 8GB RAM. When you have a laptop computer with 4GB RAM, could also be it is time to improve to atleast 8G
Python Code : GPT4All
The Colab code is on the market so that you can make the most of. Chances are you’ll use it as a reference, modify it in line with your wants, and even run it as is. It’s fully as much as you to determine easy methods to use the code to finest suit your necessities.
Clone Git Repository
!git clone --recurse-submodules https://github.com/nomic-ai/gpt4all.git
Set up required packages
cd /content material/gpt4all !python -m pip set up -r necessities.txt cd transformers !pip set up -e . cd ../peft !pip set up -e .
Coaching
!speed up launch --dynamo_backend=inductor --num_processes=8 --num_machines=1 --machine_rank=0 --deepspeed_multinode_launcher normal --mixed_precision=bf16 --use_deepspeed --deepspeed_config_file=configs/deepspeed/ds_config.json prepare.py --config configs/prepare/finetune.yaml
Obtain the CPU quantized gpt4all mannequin checkpoint
cd /content material/gpt4all/chat !wget https://the-eye.eu/public/AI/fashions/nomic-ai/gpt4all/gpt4all-lora-quantized.bin
Run conversational system
!./gpt4all-lora-quantized-linux-x86
In case you are working this in your native machine which runs on another working system than linux, use the instructions under as an alternative of the above line.
Home windows (PowerShell): ./gpt4all-lora-quantized-win64.exe Mac (M1): ./gpt4all-lora-quantized-OSX-m1 Mac (Intel): ./gpt4all-lora-quantized-OSX-intel
Full Code
!git clone --recurse-submodules https://github.com/nomic-ai/gpt4all.git cd /content material/gpt4all !python -m pip set up -r necessities.txt cd transformers !pip set up -e . cd ../peft !pip set up -e . !speed up launch --dynamo_backend=inductor --num_processes=8 --num_machines=1 --machine_rank=0 --deepspeed_multinode_launcher normal --mixed_precision=bf16 --use_deepspeed --deepspeed_config_file=configs/deepspeed/ds_config.json prepare.py --config configs/prepare/finetune.yaml cd /content material/gpt4all/chat !wget https://the-eye.eu/public/AI/fashions/nomic-ai/gpt4all/gpt4all-lora-quantized.bin !./gpt4all-lora-quantized-linux-x86
Output : GPT4All
GPT4All couldn’t reply query associated to coding accurately. This is only one occasion, cannot choose accuracy based mostly on it. It could work properly in different prompts so accuracy of the mannequin will depend on your utilization. Additionally after I ran it once more after 2 days, it really works properly for questions associated to coding. It appears they additional refined the mannequin.
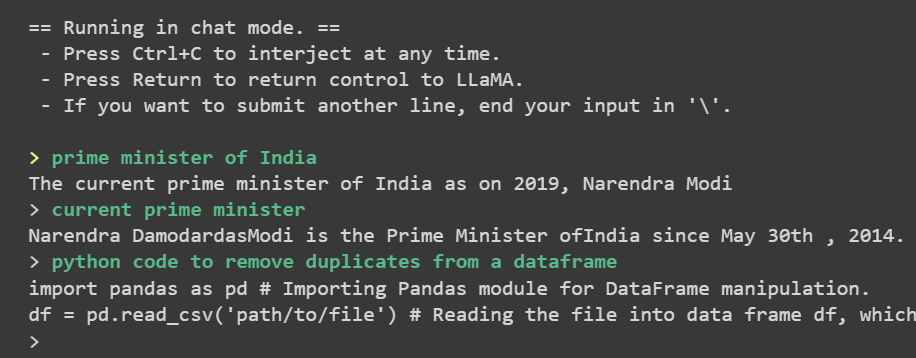
Errors Debugging
Distributed package deal does not have NCCL
In case you are dealing with this problem on Mac working system, it’s as a result of CUDA will not be put in in your machine.
Points on Home windows 10/11
Some customers reported they’re having some bizarre errors on Home windows platform. As a final resort, you possibly can set up Home windows Subsystem for Linux which permits you put in a Linux distribution in your Home windows machine after which can observe the above code.
GPT4All-J
You should be questioning how this mannequin has related identify just like the earlier one besides suffix ‘J’. It’s as a result of each of those fashions are from the identical group of Nomic AI. The one distinction is it’s skilled now on GPT-J than Llama. The advantage of coaching it on GPT-J is that GPT4All-J is now Apache-2 licensed which implies you should use it for business functions and may also simply run in your machine.
Obtain Installer File
Obtain the under installer file as per your working system. As soon as set up is accomplished, it’s essential to navigate the ‘bin’ listing inside the folder whereby you probably did set up. To launch the GPT4All Chat software, execute the ‘chat’ file within the ‘bin’ folder. The file shall be named ‘chat’ on Linux, ‘chat.exe’ on Home windows, and ‘chat.app’ on macOS
Dolly 2
Databricks group created massive language mannequin based mostly on EleutherAI’s Pythia mannequin and so they later fine-tuned on roughly 15,000 file instruction corpus. It comes underneath Apache 2 license which implies the mannequin, the coaching code, the dataset, and mannequin weights that it was skilled with are all obtainable as open supply, such you could make a business use of it to create your personal personalized massive language mannequin.
It comes with three sizes – 12B, 7B and 3B parameters.
databricks/dolly-v2-12b on pythia-12b databricks/dolly-v2-7b on pythia-6.9b databricks/dolly-v2-3b on pythia-2.8b
Reminiscence Necessities : Dolly 2
It requires a GPU with roughly 10GB RAM for 7B mannequin with 8-bit quantization. For 12B mannequin, it requires atleast 18GB GPU vRAM.
Python Code : Dolly 2
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
baseModel = "databricks/dolly-v2-12b"
load_8bit = True
tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-12b")
mannequin = AutoModelForCausalLM.from_pretrained(baseModel, load_in_8bit=load_8bit, torch_dtype=torch.float16, device_map="auto")
generator = pipeline(process='text-generation', mannequin=mannequin, tokenizer=tokenizer)
print(generator("Python code to take away duplicates from dataframe"))
Vicuna
Introduction : Vicuna
Workforce of researchers from UC Berkeley, CMU, Stanford, and UC San Diego developed this mannequin. It was wonderful tuned on Llama utilizing chat dataset extracted from ShareGPT web site. The researchers claimed the mannequin scored greater than 90% high quality of OpenAI ChatGPT-4. It is value noting that its efficiency is nearly equal to Bard. They used the coaching program of Alpaca and improved additional on two facets – multi-round conversations and lengthy sequences.
Python Code : Vicuna
You possibly can check with this publish – Vicuna Detailed Information to entry python code and an in depth description of the Vicuna mannequin.
StableVicuna
Introduction : StableVicuna
Stability AI launched StableVicuna which is a wonderful tuned model of Vicuna 13b mannequin. To make the Vicuna mannequin higher, they skilled it extra utilizing supervised finetuning (SFT). They used three completely different datasets to coach it:
- OpenAssistant Conversations Dataset, which has 161,443 human dialog messages in 35 completely different languages,
- GPT4All Immediate Generations, which is a dataset of 437,605 prompts and responses generated by GPT-3.5
- Alpaca, which is a dataset of 52,000 prompts and responses generated by text-davinci-003 mannequin.
They used trlx to coach a reward mannequin. This mannequin was first arrange utilizing their additional SFT mannequin. The reward mannequin was skilled utilizing three datasets which have human preferences:
- OpenAssistant Conversations Dataset with 7213 choice samples.
- Anthropic HH-RLHF with 160,800 labels from individuals who say what they give thought to how useful or innocent AI assistants are.
- Stanford Human Preferences with 348,718 human preferences about responses to questions or directions in several areas, like cooking or philosophy.
Lastly, the SFT mannequin is skilled utilizing RLHF with trlX by way of a course of known as Proximal Coverage Optimization. That is how StableVicuna was constructed
Reminiscence Necessities : StableVicuna
To run 4bit GPTQ StableVicuna mannequin, it requires approximate 10GB GPU vRAM.
Efficiency Points : StableVicuna
Stability AI claims that this mannequin is an enchancment over the unique Vicuna mannequin, however many individuals have reported the alternative. This mannequin does extra ‘hallucination’ than the unique mannequin, leading to worse responses. In easy phrases it means the mannequin generates inaccurate output which isn’t an precise reply of the immediate. Since these fashions have been newly launched, rigorous analysis is but to be executed. It’s attainable that this mannequin could carry out higher on some duties, however a lot worse on others.
Python Code : StableVicuna
We will run the mannequin utilizing Textual content Era WebUI which makes it simple to run open supply LLM mannequin. The code under performs 4-bit quantization which lessens the reminiscence necessities of the mannequin and make it attainable to run on lesser VRAM.
%cd /content material !apt-get -y set up -qq aria2 !git clone -b v1.2 https://github.com/camenduru/text-generation-webui %cd /content material/text-generation-webui !pip set up -r necessities.txt !pip set up -U gradio==3.28.3 !mkdir /content material/text-generation-webui/repositories %cd /content material/text-generation-webui/repositories !git clone -b v1.2 https://github.com/camenduru/GPTQ-for-Llama.git %cd GPTQ-for-Llama !python setup_cuda.py set up !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/uncooked/major/config.json -d /content material/text-generation-webui/fashions/stable-vicuna-13B-GPTQ -o config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/uncooked/major/generation_config.json -d /content material/text-generation-webui/fashions/stable-vicuna-13B-GPTQ -o generation_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/uncooked/major/special_tokens_map.json -d /content material/text-generation-webui/fashions/stable-vicuna-13B-GPTQ -o special_tokens_map.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/resolve/major/tokenizer.mannequin -d /content material/text-generation-webui/fashions/stable-vicuna-13B-GPTQ -o tokenizer.mannequin !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/uncooked/major/tokenizer_config.json -d /content material/text-generation-webui/fashions/stable-vicuna-13B-GPTQ -o tokenizer_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/stable-vicuna-13B-GPTQ/resolve/major/stable-vicuna-13B-GPTQ-4bit.compat.no-act-order.safetensors -d /content material/text-generation-webui/fashions/stable-vicuna-13B-GPTQ -o stable-vicuna-13B-GPTQ-4bit.compat.no-act-order.safetensors %cd /content material/text-generation-webui !python server.py --share --chat --wbits 4 --groupsize 128
Alpaca GPT-4 Mannequin
Introduction : Alpaca GPT-4
You have got already learnt about Alpaca within the earlier part of this publish. Right here some researchers have improved the unique Alpaca mannequin by coaching it on GPT-4 dataset. Keep in mind the unique Alpaca mannequin from stanford researchers was based mostly on GPT-3 mannequin. This GPT-4 mannequin was skilled on Llama 13 billion (13B) parameters sized mannequin.
Python Code : Alpaca GPT-4
Python program for Alpaca GPT-4 mannequin is defined right here – Alpaca GPT-4 Detailed Information.
Cerebras-GPT
Introduction : Cerebras-GPT
A few of it’s possible you’ll not have heard of Cerebras Programs earlier than. They aren’t as well-known as NVIDIA, which is legendary for manufacturing GPUs however they too are a know-how firm specializing in manufacturing high-performance computing techniques. They lately launched open supply challenge containing seven GPT based mostly language fashions with measurement 111 Million, 256 Million, 590 Million, 1.3 Billion, 2.7 Billion, 6.7 Billion, and 13 Billion parameters.
The perfect half about these fashions is that they’re obtainable free of charge and can use it for business functions because it comes underneath the Apache 2.0 license, whereas Llama comes with “Non-Business” license which implies they’re free however can solely use for analysis functions.
Additionally they’re 7 completely different sizes of fashions obtainable which implies you’ve got numerous fashions to decide on as per your {hardware} configurations. Choose smaller one in case your {hardware} doesn’t enable to experiment large-sized fashions.
Reminiscence Necessities : Cerebras-GPT
It requires GPU with 12GB RAM to run 1.3B parameters sized Cerebras-GPT mannequin.
Python Code : Cerebras-GPT
In this system under, we’re utilizing python package deal named xTuring developed by group of Stochastic Inc. It permits builders to wonderful tune completely different massive language fashions effectively. They’ve additionally made syntax very readable and straightforward to observe.
Right here we wonderful tuned the Cerebras-GPT mannequin utilizing
Alpaca dataset
This Colab code might be referred for testing. Within the code under we’re utilizing Cerebras-GPT 1.3B mannequin
Set up the xTuring library
!pip set up xturing --upgrade
Generate dataset
!wget https://d33tr4pxdm6e2j.cloudfront.web/public_content/tutorials/datasets/alpaca_data.zip !unzip alpaca_data.zip
Load the dataset and initialize the mannequin
from xturing.datasets.instruction_dataset import InstructionDataset
from xturing.fashions.base import BaseModel
instruction_dataset = InstructionDataset("/content material/alpaca_data")
# Initializes the mannequin
mannequin = BaseModel.create("cerebras_lora_int8")
High-quality tune the mannequin
mannequin.finetune(dataset=instruction_dataset)
Construct ChatBot
output = mannequin.generate(texts=["prime minister of India?"])
print("Generated output by the mannequin: {}".format(output))
High-quality tuning the mannequin takes numerous processing time so one must be very affected person. As soon as wonderful tuning is accomplished, it can save you the mannequin for future reference.
# Save Mannequin
mannequin.save("/path_directory")
# Load a fine-tuned mannequin
finetuned_model = BaseModel.load("/path_directory")
In case the loading mannequin returns error AssertionError: We weren't capable of finding the xturing.json file on this listing, use the code under.
mannequin = BaseModel.create("cerebras",weights_path="/path_directory")
GPT-J 6B
Introduction : GPT-J 6B
GPT-J 6B was developed by researchers from EleutherAI. It is not a brand new mannequin because it was launched in second half of 2021. It has 6 billion parameters. It isn’t as massive as Meta’s Llama however it performs properly on numerous pure language processing duties comparable to chat, summarization, and query answering. Excessive measurement of the mannequin doesn’t essentially imply extra correct. It was skilled for 402 billion tokens on a TPU v3-256 pod.
Like Cerebras-GPT, GPT-J 6B are additionally licensed underneath Apache 2.0 License, which lets you use it for business functions.
Python Code : GPT-J 6B
You possibly can refer the colab pocket book for making an attempt it out.
Python code for GPT-J 6B is just like the code for Cerebras-GPT. The one change is the initialisation of the bottom mannequin BaseModel.create("gptj_lora_int8") as an alternative of BaseModel.create("cerebras_lora_int8")
OpenChatKit Mannequin
Introduction : OpenChatKit
OpenChatKit is an open-source massive language mannequin for creating chatbots, developed by Collectively. They collaborated with LAION and Ontocord to create the coaching dataset. It comes underneath an Apache-2.0 license, with full entry to supply code, mannequin weights, and coaching datasets. The goal of the challenge is to advertise inclusivity, transparency, and robustness in open-source basis fashions. It’s good at performing numerous duties together with summarization and query answering inside context, info extraction, and textual content classification.
It has 20 billion parameters skilled on 43 million directions sized coaching dataset. It’s known as GPT-NeoXT-Chat-Base-20B It additionally has yet one more mannequin based mostly on ElutherAI’s Pythia-7B mannequin known as Pythia-Chat-Base-7B which is a 7B parameter language mannequin.
Demo : OpenChatKit
You possibly can take a look at demo of the mannequin on Hugging Face web site
Reminiscence Requirement : OpenChatKit
Pythia-Chat-Base-7B can run on a single GPU with 12GB RAM.
Python Code : Pythia-Chat-Base-7B
You should utilize the colab pocket book for Pythia-Chat-Base-7B.
# GPU Configuration !nvidia-smi # Set up conda !wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && chmod +x Miniconda3-latest-Linux-x86_64.sh && ./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/native # Organising conda setting !conda set up mamba -n base -c conda-forge -y !git clone https://github.com/orangetin/OpenChatKit.git --branch colab-example && cd OpenChatKit && mamba env create -f setting.yml !supply activate OpenChatKit && pip set up bitsandbytes # Obtain and run mannequin !supply activate OpenChatKit && python OpenChatKit/inference/bot.py --model togethercomputer/Pythia-Chat-Base-7B --load-in-8bit
ChatRWKV
Introduction : ChatRWKV
ChatRWKV is powered by RWKV (100% RNN) language mannequin, which is the one RNN that may match transformers in high quality and scaling, whereas being quicker and saves VRAM. This mannequin was wonderful tuned on Alpaca, code-alpaca dataset.
Demo : ChatRWKV
Demo of the mannequin is on the market on Hugging Face web site
Python Code : ChatRWKV
You possibly can construct internet interface through the use of the code obtainable on github
Flan-T5
Google launched the open-source LLM mannequin Flan-T5. It’s multilingual and makes use of instruction fine-tuning that improves the efficiency and value of pretrained language fashions. It’s a variant of T5 that generalises higher and outperforms T5 in lots of Pure Language Processing duties.
OPT
OPT is a language mannequin that Meta launched earlier than Llama. When Llama was launched, it outperforms OPT. OPT is an mannequin which shouldn’t be thought-about now as many higher open supply fashions are already obtainable available in the market as proven above.
Verdict: The Finest Open Supply ChatGPT Alternate options
The record of open-source options to ChatGPT is rising so it is higher to take the time to check these fashions in line with your wants. Please see the comparability under.
- Accuracy : Alpaca GPT-4 and Vicuna fashions are essentially the most correct and constant fashions amongst all open supply fashions. When you have entry to high-powered machines, these two fashions are advisable.
- Reminiscence : GPT4ALL doesn’t require costly {hardware} when it comes to reminiscence necessities, can run on CPU with 8GB RAM. Go for it when you’ve got price range/low-end machine. It additionally do not compromise when it comes to accuracy.
- Business Use : If you wish to use the mannequin for business functions, go for Llama2, GPT4All-J, Dolly 2, OpenChatKit, Cerebras-GPT and GPT-J 6B. They can help you distribute your software program for enterprise use.
[ad_2]