

{kind=link}
[ad_1]
To the readers, I’m Aryan Gupta(@guptaaryan16), an EE Junior at IIT Roorkee, and this summer time, I had an opportunity to work on PyTorch-Ignite’s Code-Generator undertaking, a tailored internet software to assist machine studying researchers and fanatics and in addition maintaining in thoughts the rising Kaggle neighborhood.
Let’s see the undertaking itself. Code-Generator is a Vue.js software that streamlines the method of engaged on machine studying duties. The app generates preconfigured code templates for duties like imaginative and prescient classification, textual content classification, and different widespread themes in ML competitions.
The intention is to not be one other abstraction over PyTorch and PyTorch-Ignite. As a substitute, Code-Generator is an online app that generates the boilerplate code, which implies you continue to have full management over the generated code. You can begin by deciding on the minimal template like ‘text-classification’ and switch choices on or off based on your wants, choose a specific logger like Tensorboard or an arg-parser like Python-Fireplace. This app will be useful in information science competitions on Kaggle or in writing papers, particularly with straightforward integration of loggers and checkpoint handlers. Additionally, the templates are well-tested on CI and hopefully would require minimal modifications to work in your workflows.
This app was created with the good efforts of members of the PyTorch-Ignite neighborhood, notably @ydcjeff @trsvchn @vfdev-5.
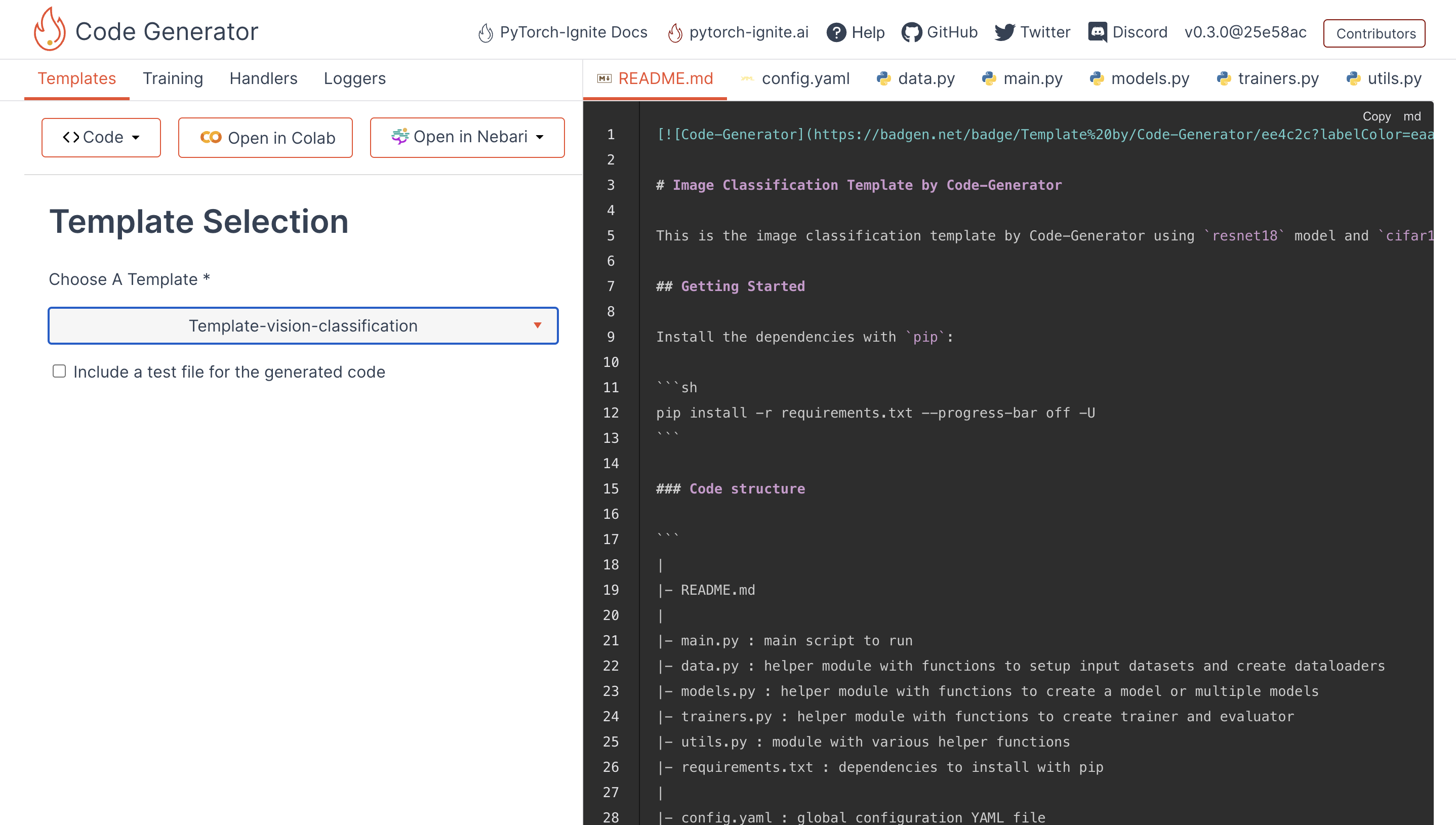
My duties had been primarily to work on options that would enhance the reproducibility-related options of the templates. Additionally, I needed to contribute to new options and libraries which will be greatest for experiments’ configuration administration. My contributions to the undertaking had been primarily three-fold, and are detailed under.
1. Engaged on enhancing templates and present reproducibility scope of the outcomes from experiments
On this half, I labored on enhancing the readability and API of the templates. This led me to make some essential API modifications and check the present libraries used for writing the analysis literature in information science and Kaggle competitions. One humorous error we caught within the PyYaml undertaking was
There have been different issues as properly, like not having the ability to retailer Python objects utilizing PyYAML API. This led us to undertake OmegaConf.DictConfig because the API commonplace for sustaining config information within the templates. This labored nice on testing and is properly maintained by the builders. Additionally, strategies like decision of config dict are very properly written on this OmegaConf undertaking.
Additionally, we added help for Hydra and Python-Fireplace as they’re nice by way of configuration administration and in addition labored very properly with PyTorch-Ignite. In addition they enable overriding present configurations utilizing the next bash instructions.
Observe that you need to use ++ just for overrides not current in config.yaml for the Hydra CLI use. For more information, do test the docs for OmegaConf, Python-Fireplace and Hydra .
Among the associated PRs will be discovered right here: #292 #300 #302
2. Integration with Nebari and different infrastructure administration instruments
I labored on testing this nice infrastructure instrument, Nebari, which is used for managing GPU clusters and Cloud infrastructure for information scientists and different professionals. It supplies a JupyterHub interface, which will be very useful for deploying code and operating instruments. So, to elucidate the mixing of my undertaking with Nebari, firstly, I want to focus on how the undertaking shops the templates with a specific configuration.
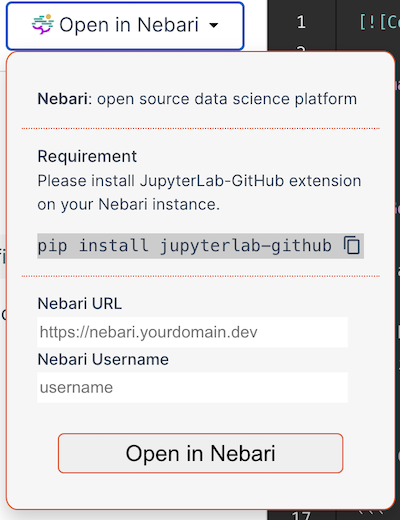
To elucidate it shortly, let’s see how the app works while you click on on Open in Nebari . After the button is clicked, we use a netlify operate to commit a zipper file and Jupyter pocket book utilizing github/octokit to the pytorch-ignite/nbs repository. We will see a dedicated pocket book instance under. To know this higher, you possibly can learn the code in pytorch-ignite/code-generator/capabilities/nebari.js.
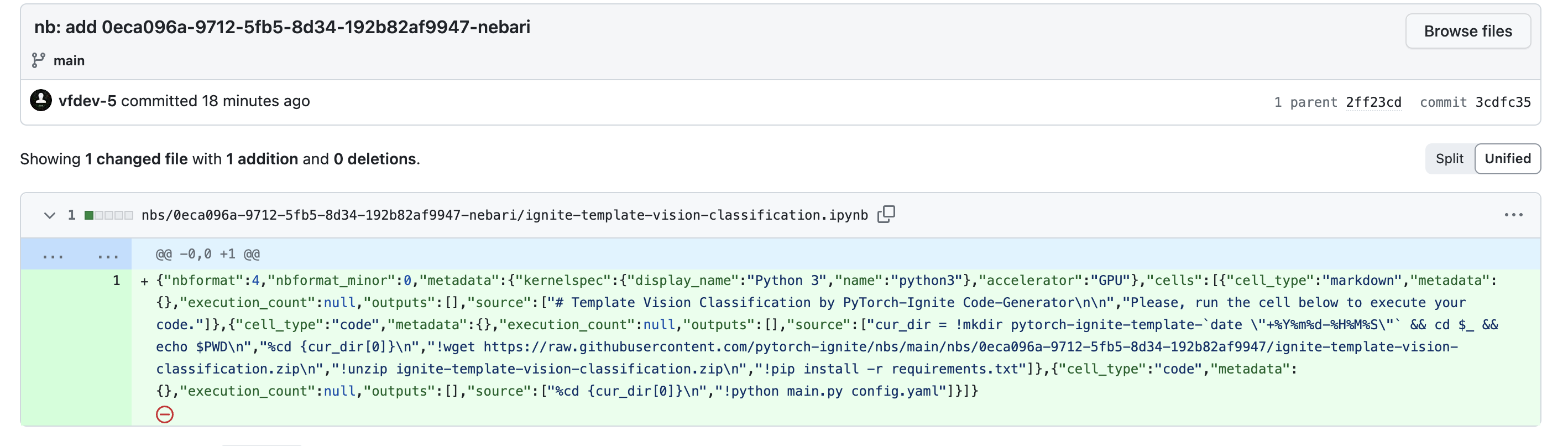
Now, to combine this with the Nebari server, we used an extension known as Jupyterlab-Github. I wrote a netlify operate to create a URL that may use this extension, open the generated hyperlink within the new tab, pull the pocket book dedicated by the above netlify operate, and open this pocket book within the server. An instance will be seen right here. Fairly cool, proper?
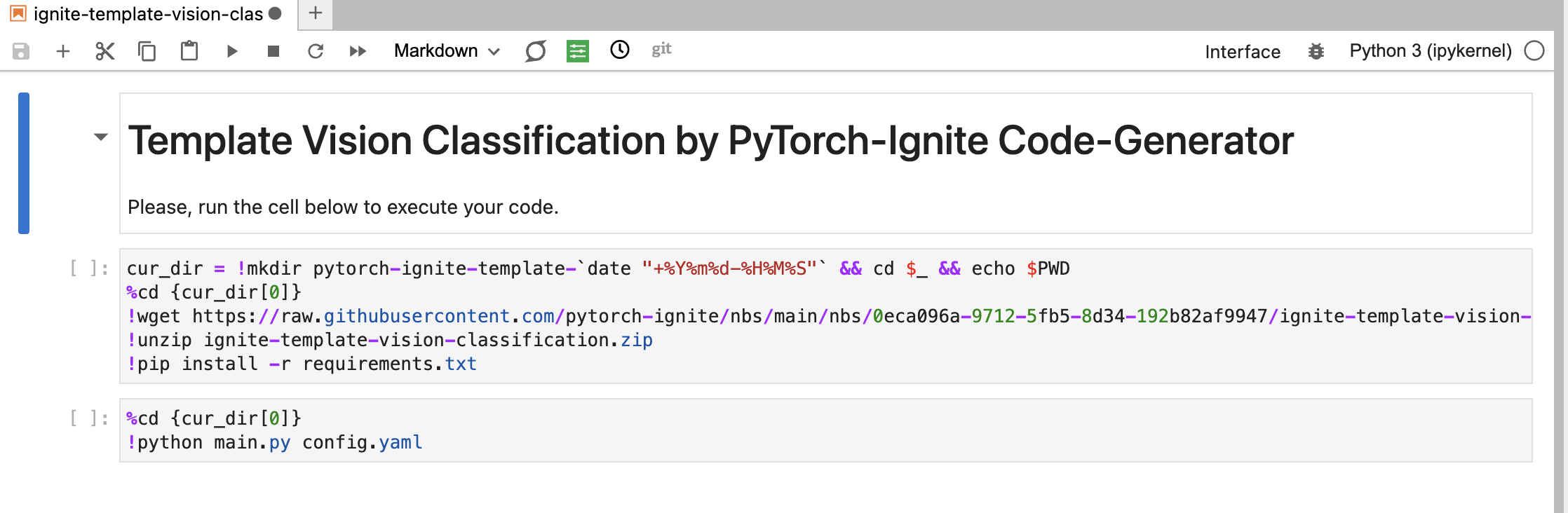
For this, I respect the Jupyter neighborhood’s extension ecosystem. They’ve nice extensions for the whole lot and perhaps sooner or later, I may fit or attempt to add extra extensions to extend the performance within the app. Additionally, I want to thank the Nebari-dev neighborhood right here, who supplied such nice help in testing this within the Nebari server.
Among the associated PRs will be discovered right here: #265 #314
3. The modifications within the CI and different Vuejs primarily based components of the code base (primarily primarily based on JS)
I needed to contribute some JavaScript-based code to the app, however since I had not labored on a JS undertaking earlier than, I wanted to study the fundamentals earlier than contributing to those points, particularly Vue.js 🙁 . So, I attempted to study by studying some on-line tutorials and documentation. I notably preferred this tutorial collection on YouTube.
To elucidate extra about how one can generates templates, let’s assume I made some information like foremost.py, mannequin.py, and utils.py as a template. Now we use the ejs undertaking so as to add and choose particular choices and render them throughout runtime within the browser. As an example this, allow us to take an instance from the templates.
Now, as you possibly can see, there are some commented codes. That is a part of JS, which helps choose totally different configurations of argparsers. Appears straightforward, proper?
However it may be difficult to handle, and we additionally want to make sure we fulfill the lint formatting for the CI (which will be fairly tough with templates 🙁 ). Nonetheless, these JS options will be very highly effective, and we are attempting to enhance these as a lot as potential. By the best way, in case you are confused about the place this it.argparser selector got here from, higher test the undertaking, however the quick reply is it comes from a metadata.json file that maintains the choices for all of the templates within the app.
Among the associated PRs will be discovered right here: #283 #288
The Code-Generator undertaking appears to be transferring ahead at a terrific tempo and is anticipated to have many extra additions sooner or later. Beginning and sustaining a brand new undertaking is difficult in open supply and may have a really excessive threat/reward ratio. Nonetheless, good communities strive their greatest to make and keep initiatives that may be useful for the utmost variety of folks and scale back the friction for brand spanking new folks coming into the neighborhood. Listed below are a number of the points I recommend and may fit on sooner or later.
1. Separate metadata.json for every template
We’re contemplating offering separate metadata.json information for every template or one thing just like that sooner or later. I proposed a problem to the undertaking for a similar right here and can attempt to work on this sooner or later.
2. Script to contribute new templates
Since it’s arduous for Knowledge science fanatics to study JS and contribute templates simply, which additionally appears to be a degree of friction in adopting the app, we proposed including a script that may assist make JS and CI-related modifications to the app as advised within the problem right here. This problem could take a little bit of arduous work, however it may be a terrific addition to the app.
3. Extra templates and have choices
We’ll add extra templates and have choices sooner or later to the undertaking. Templates like object detection, textual content summarisation, and diffusion fashions will be a wonderful addition to the undertaking.
P.S. For those who really feel excited concerning the undertaking, please be happy to recommend extra modifications and contribute to the undertaking.
This internship expertise elevated my confidence in sustaining an open-source codebase and understanding how one can check capabilities and debug modifications. It additionally helped me perceive the worth of real-life design choices and CI and the way they will considerably affect the undertaking for the nice or the dangerous. Among the greatest practices I discovered within the open-source initiatives are listed under.
1. Attempt to make the code modifications extra developer centric
After we attempt to write new code or change the present information, we regularly attempt to do it in a method that provides most options and sometimes neglect to jot down high quality code. Whereas engaged on new modifications, attempt to manage the code higher and simplify the widespread code in a separate utils file. This could make the codebase higher and extra accessible for different builders to view and perceive. Additionally, go away significant quick feedback, as it will probably save a while for the subsequent Developer that lands in your undertaking.
2. Attempt to have separate PRs for giant modifications
Whereas making a pull request(PR) appears very thrilling on a undertaking, it’s best to know what and the way a lot you wish to accomplish in a single pull request. Generally, we will make too many useful modifications in a single pull request, making testing and eradicating all of the bugs troublesome. This problem was evident in my time as an intern as a few of my PRs had been terribly formatted, and this led to me fully rebasing them and making 4-5 extra PRs to the primary undertaking to take away many bugs in these modifications. This was painful for me and my mentor, however I thank him for serving to me with nice options and evaluations.
Additionally, this expertise elevated my studying and helped me enhance the standard of my pull requests. So don’t be afraid to make errors; study from them and make your method on this unimaginable world of OSS!
On this part, I want to thank my mentor, @vfdev-5, and different members of the PyTorch-Ignite neighborhood for serving to me on this internship. Additionally, I want to thank the folks at Quansight-Labs for offering me with such a terrific alternative, particularly @rgommers, @trallard, @melissawm, and others for his or her invaluable steerage and time throughout this internship.
References
[ad_2]